

Cómo hice en Python el curso de Machine Learning de Andrew Ng - Ejercicio 1
Mi camino en el aprendizaje de Machine Learning comenzó con el curso de Andrew Ng de Coursera, tal y como comenté en el post Como empecé a aprender Machine Learning.
Este curso está dividido en bloques semanales que contienen videos explicativos y ejercicios evaluables escritos para realizarse en Octave o Matlab.
Actualmente, uno de los lenguajes más popular para desarrollar los modelos de Machine Learning es Python. Por lo tanto, me he propuesto volver a realizar estos ejercicios evaluables, pero en esta ocasión en Python y usando los ficheros Jupyter Notebook que facilitan el desarrollo de una memoria escrita añadiendo líneas de código y su resultado.
Puedes ver el resultado aquí en mi repositorio de Github.
Ejercicio 1 - Regresión Linear
El primer ejercicio del curso consiste en implementar modelos de regresión linear con una variable y con multiples variables, así como visualizarlos y como se comportan respecto a los datos de entrada.
1. Regresión Linear con una variable
En este primer apartado del ejercicio, hay que implementar un modelo de regresión linear con una variable para predecir los beneficios de un food truck de una franquicia de restaurantes. La cadena tiene varios food truck por varias ciudades y tiene datos de beneficios en función de las poblaciones.
1.1 Visualizar los datos
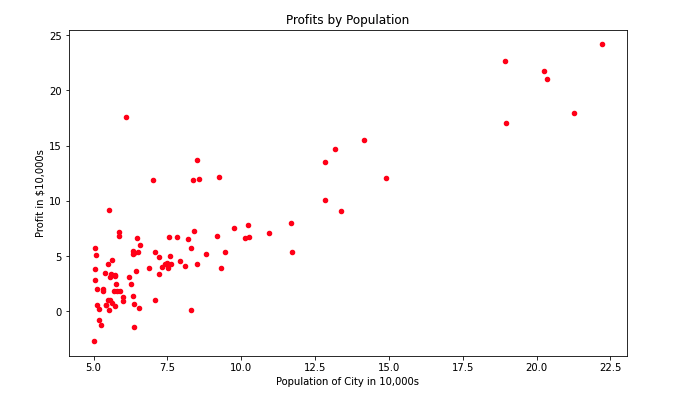
En primer lugar voy a visualizar los datos que tengo almacenados en el archivo que me proporcionan. La primera columna es la población de la ciudad y la segunda, el beneficio (si es positivo) o la pérdida (si es negativo).
| Población | Beneficio | |
|---|---|---|
| 1 | 6.1101 | 17.5920 |
| 2 | 5.5277 | 9.1302 |
| 3 | 8.5186 | 13.6620 |
| 4 | 7.0032 | 11.8540 |
| 5 | 5.8598 | 6.8233 |
Con las siguientes líneas de código, usando matplotlib y una gráfica de dispresión, podemos representar los datos proporcionados:
data.plot(kind='scatter', x='population', y='profit', figsize=(10,6), color='red')
plt.title('Profits by Population')
plt.xlabel('Population of City in 10,000s')
plt.ylabel('Profit in $10,000s')
plt.show()
1.2 Función de coste
El objetivo de la regresión linear es minimizar la función de coste J(𝜃), es decir, minimizar la diferencia entre los datos reales y la hipótesis, tal y como muestran las siguientes ecuaciones:
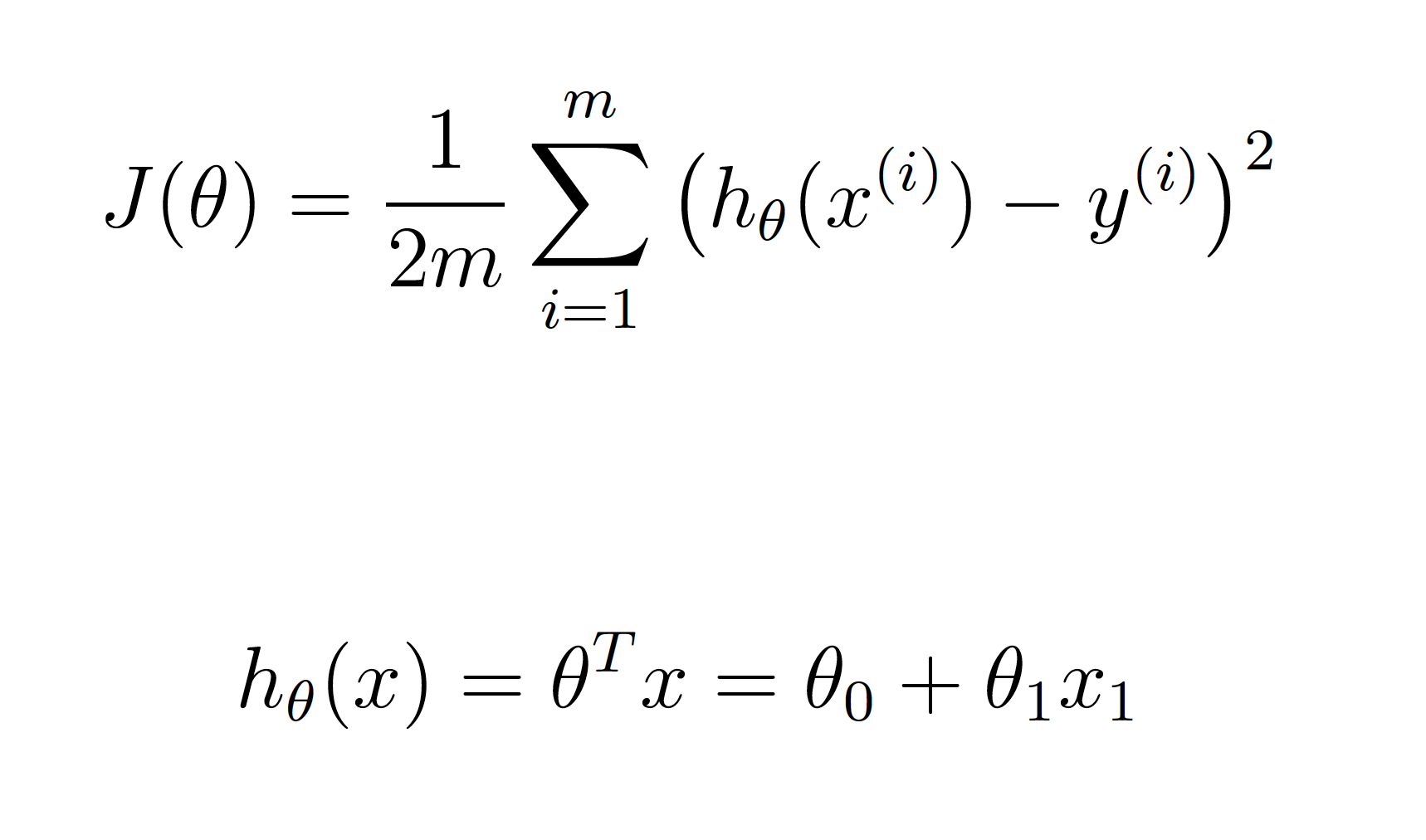
Para tener en cuenta el valor de 𝜃0, es necesario añadir a X una columna adicional de unos al principio. Por tanto las variables X e y quedarían de la siguiente manera:
X = data['population'].to_numpy()
X = np.stack([np.ones(m), X], axis=1)
y = data['profit'].to_numpy().reshape((m, 1))
Para calcular la función de coste en Python, dados los parámetros de entrada X, y y theta la función computeCost devuelve J como el valor de la función de coste para esos valores:
def computeCost(X, y, theta):
# number of training examples
m = len(y)
h = np.dot(X, theta)
J = (1/(2*m)) * np.sum(np.square(h - y))
return J
Para comprobar si está correcto, en el ejercicio original del curso prueban con dos valores de 𝜃 y los valores concuerdan.
| 𝜃 | coste calculado | coste esperado |
|---|---|---|
| [0 ; 0] | 32.0727 | 32.07 |
| [-1 ; 2] | 54.2425 | 54.24 |
1.3 Gradiente Descendente
La finalidad del gradiente descendente es ayudar a minimizar la función de coste ajustando los valores de 𝜃 mediante la repetición de actualizaciones de los valores de 𝜃, según la siguiente ecuación:
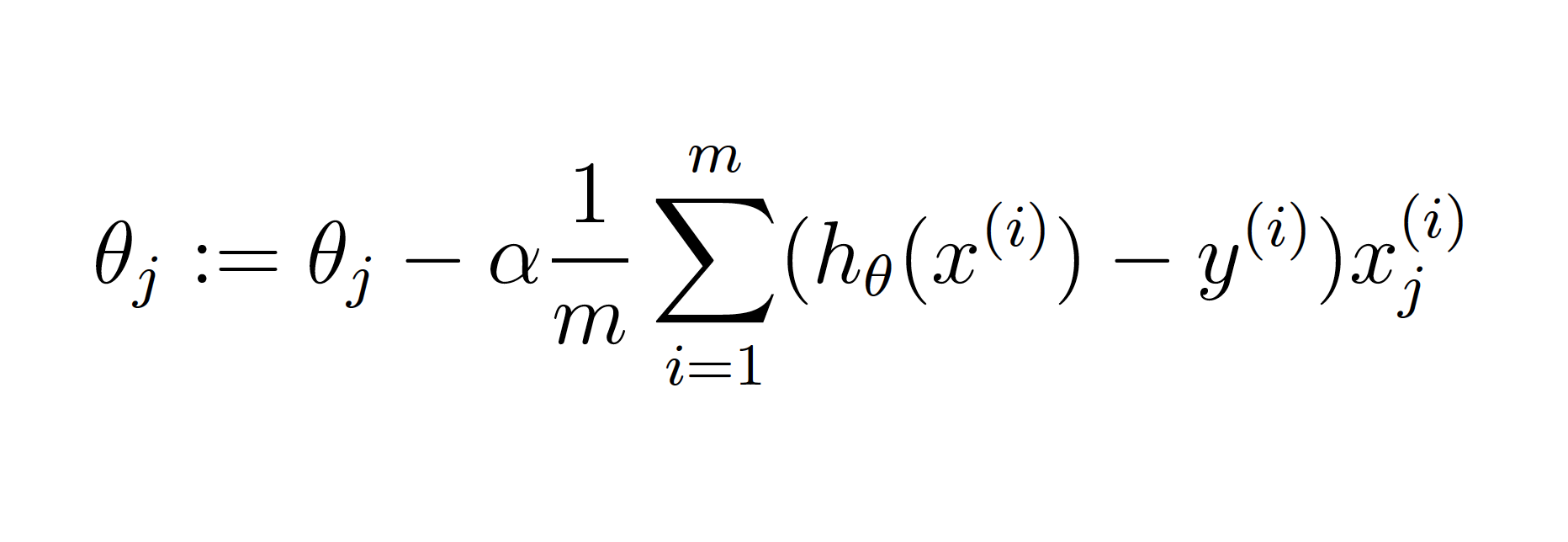
En cada iteración del gradiente descendente se actualizan simultaneamente todos los valores de 𝜃 y el valor de la función de coste en cada caso se va acercando al valor mínimo.
Para implementar el proceso del gradiente descendente, dados los parámetros X, y, theta, alpha e iterations la función gradientDescent devuelve theta, con los últimos valores de 𝜃, y J_history, con el registro de todos los valores de la función de coste a lo largo del gradiente.
def gradientDescent(X, y, theta, alpha, iterations):
# number of training examples
m = len(y)
# cost over the iterations
J_history = np.zeros((iterations, 1))
# Make a copy of theta, which will be updated by gradient descent
theta = theta.copy()
for i in range(iterations):
# Perform a single gradient step on the parameter vector theta.
h = np.dot(X, theta)
t0 = theta[0] - ( alpha * (1/m) * np.sum(h - y) )
t1 = theta[1] - ( alpha * (1/m) * np.sum(np.dot( X[:,1].T , (h - y) ) ) )
theta[0] = t0
theta[1] = t1
# Save the cost J in every iteration
J_history[i,:] = computeCost(X, y, theta)
return theta, J_history
Para comprobar si está correcto, en el ejercicio original inicializan los valores de 𝜃 a cero, α a 0.01 y el número de iteraciones a 1500. Después de realizar el gradiente descendente, el valor de la función de coste es 4.4834, mucho menor que el valor anterior de 32.0727. Asimismo, los valores de 𝜃 que se esperan y los obtenidos concuerdan.
| 𝜃 calculada | 𝜃 esperada |
|---|---|
| [-3.6303 ; 1.1664] | [-3.6303 ; 1.1664 ] |
1.4 Visualizar el ajuste linear
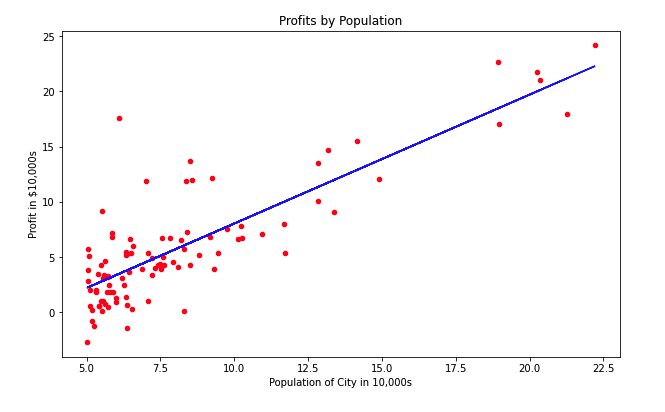
Para visualizar el ajuste de modelo de regresión superponemos la función linear a los datos de entrada, y quedaría de la siguiente manera:
# Plot the data in a scatter plot
data.plot(kind='scatter', x='population', y='profit', figsize=(10,6), color='red')
plt.title('Profits by Population')
plt.xlabel('Population of City in 10,000s')
plt.ylabel('Profit in $10,000s')
# Plot the linear fit over the scatter plot
h = np.dot(X, theta)
plt.plot(X[:,1], h, color='blue')
plt.show()
1.5 Estimar nuevos valores
Una vez que tenemos el modelo de regresión linear podemos estimar valores de beneficios con nuevos datos de población. En el ejercicio original, nos piden calcular la predicción de beneficios en áreas de 35000 y 70000 personas. Con estos datos y los valores de 𝜃 obtenidos, podemos calcular las estimaciones de la siguiente forma:
# Predict values for population sizes of 35,000 and 70,000
predict1 = np.dot([1, 3.5] , theta) * 10000
predict2 = np.dot([1, 7] , theta) * 10000
| población | predicción |
|---|---|
| 35000 | 4519.7679 |
| 70000 | 45342.4501 |
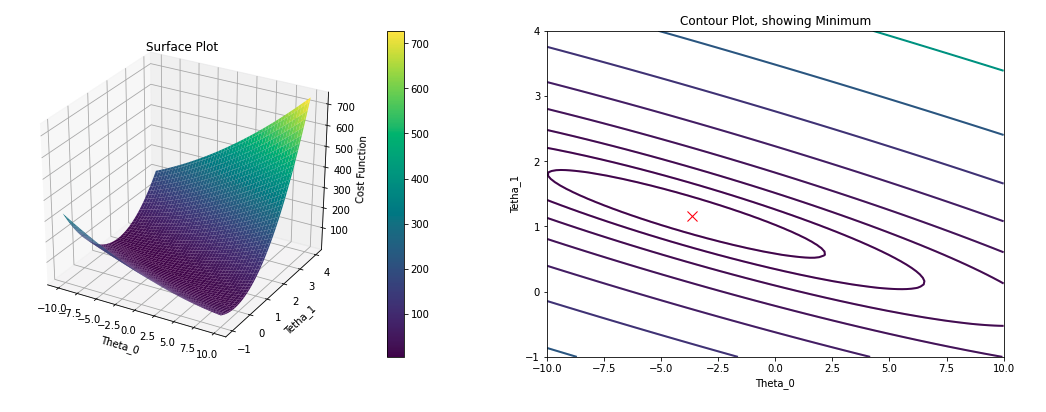
1.6 Visualizar la función de coste
Para entender mejor la función de coste, se puede representar en función de los valores de 𝜃, tanto en dos como en tres dimensiones, utilizando las herramientas de surface y contour de matplotlib. Puedes ver cómo lo he implementado con más detalle aquí en mi repositorio en Github.
2. Regresión Linear con multiples variables
En el segundo apartado del ejercicio, hay que implementar un modelo de regresión linear con multiples variables para predecir precios de casas. Para ello, se parte de un conjunto de datos con información de casas vendidas recientemente.
2.1. Entender los datos
De nuevo voy a visualizar los datos proporcionados para entenderlos mejor. En este caso tenemos tres columnas, las dos primeras corresponden con X: el tamaño de la casa (en pies al cuadrado) y el número de dormitorios; y la tercera columna, el precio de la casa, es y.
| Tamaño | Dormitorios | Precio | |
|---|---|---|---|
| 0 | 2104 | 3 | 399900 |
| 1 | 1600 | 3 | 329900 |
| 2 | 2400 | 3 | 369000 |
| 3 | 1416 | 2 | 232000 |
| 4 | 3000 | 4 | 539900 |
2.2. Normalizar
Observando los valores de entrada, el tamaños de las casas tiene una escala mucho mayor que el número de dormitorios. Por tanto, cuando los parámetros tienen orden de magnitudes muy diferentes es preferible realizar una normalización para que el gradiente descendente sea más eficiente:
def featureNormalize(X):
# Initilize the values
X_norm = X;
num_features = X.shape[1]
mu = np.zeros((1, num_features))
sigma = np.zeros((1, num_features))
# Compute the mean of each feature storing it in mu
mu = np.mean(X)
# Compute the standard deviation of each feature storing it in sigma.
sigma = np.std(X)
# calculate the mean normalization
X_norm = (X - mu)/sigma
return X_norm, mu, sigma
Del mismo modo que en el caso con una sola variable es necesario añadirle a X, una columna adicional para tener en cuenta el valor de 𝜃0:
# Set the variables
m_multi = len(data_multi)
X_multi = data_multi.iloc[:,0:2].to_numpy()
y_multi = data_multi.iloc[:,2].to_numpy().reshape((m_multi, 1))
# Normalize X
X_multi, mu, sigma = featureNormalize(X_multi)
# Add the intercept term to X
X_multi = np.concatenate([np.ones((m_multi, 1)), X_multi], axis=1)
2.3. Función de coste y Gradiente descendente
El cálculo de la función de coste se realiza de la misma manera que en el caso con una sola variable. No obstante, con el gradiente descendente si son necesarios algunos cambios:
def gradientDescentMulti(X, y, theta, alpha, iterations):
# Initialize some useful values
m = len(y) # number of training examples
features = X.shape[1] # number of features
J_history = np.zeros((iterations, 1)) # cost over the iterations
# Make a copy of theta, which will be updated by gradient descent
theta = theta.copy()
for i in range(iterations):
# Perform a single gradient step on the parameter vector theta.
h = np.dot(X, theta)
t = theta
for j in range(features):
t[j,:] = theta[j,:] - ( alpha * (1/m) * np.sum(np.dot( X[:,j].T , (h - y) ) ) )
theta = t
# Save the cost J in every iteration
J_history[i,:] = computeCostMulti(X, y, theta)
return theta, J_history
Para comprobar el gradiente descendente se inicializan los parámetros α a 0.01, las iteraciones a 400 y los valores de 𝜃 a 0. Tras implementar el gradiente obtengo los siguientes valores:
| 𝜃 | Coste |
|---|---|
| [ 119999.4136 ; 148539.6856 ; -104839.1981 ] | 2.06491168e+09 |
2.4. Estimar nuevos valores
Con estos valores finales de theta podemos estimar el precio de una casa de 1650 pies al cuadrado y 3 dormitorios:
# Normalize the example to predict
house = np.array([[1650, 3]])
house_norm = (house - mu)/sigma
house_norm = np.concatenate([np.ones((1, 1)), house_norm], axis=1)
# Estimate the price using alpha = 0.3
predict = np.dot(house_norm, theta_lr_1)
| Tamaño | Dormitorios | Predicción |
|---|---|---|
| 1650 | 3 | 293238 |
Hasta aquí el primer ejercicio del curso de Machine Learning de Andrew Ng.
La primera vez que realicé este ejercicio aprendí muchísimo y me enfrenté a pequeñas dificultades, tanto en lo matemático como en la programación para Octave. En esta ocasión, si bien los conocimientos estaban mucho más claros, también me he enfrentado a pequeños obstáculos al adaptar el código a Python. No obstante, todos ellos me han servido para afianzar mis habilidades programando en Python.
Proximamente iré implementando el resto de ejercicios del curso en Python y escribiré nuevos post sobre como los desarrollé.
Gracias por leer hasta aquí y, ¡nos vemos en el siguiente post!



